小样本学习
CLIP
一般的图像分类是把图片用backbone编码成一个feature vector,然后用一个classifier weight matrix W 乘上得到分类结果,$W_i$是class i的 prototype weight vector
CLIP的 zero shot 迁移范式是把visual backbone 和 text encoder 在大规模有噪音的数据集上使用对比学习预训练之后,不 fine tune 直接拿来作图像分类,给定K个图像类别,包括它们的名字(natural language name) ${C_1, C_2, …, C_k}$,CLIP把 name 填到预先定义好的 prompt 模板 H 里,然后用 text encoder 编码得到 classifier weight $W_i$,
CoPo, Learning to prompt for vision- language models, arXiv
与CLIP的区别在于没有用手工定义的prompt,而是用了一个 continuous prompt,它创建了L个随机初始化的 soft tokens,每个D维,然后用S和class name concat起来经过bert得到W
CLIP-Adapter: Better Vision-Language Models with Feature Adapters, arXiv ✅
直接对feature和W做变换得到task-specific feature,并且使用门控残差连接原本的信息
作者说如果下游任务和预训练用的数据集之间的semantic gap比较大,那么就需要更多的task-specific信息,即让$\alpha$大一点,选取更多的新feature,反之相反,如果$\alpha=0$效果并不好,即完全使用新的feature,原因作者认为是过拟合
作者说单纯用visual adapter要比单纯用text adapter或一起用要好,因为visual features在预训练和fine tuning阶段 semantic gap更大
NLP
任务型对话
- [2021-EMNLP] Effective Sequence-to-Sequence Dialogue State Tracking, arXiv ✅
- 作者提了几个观点:1.Masked span prediction比自回归语言模型的预训练方式更适合迁移到DST任务 2. 在文本摘要任务上预训练可以对迁移到DST任务有帮助,作者用了Pegasus中提出的Gap Sentence Prediction作为目标在文本摘要任务上预训练 3. 对于Seq2Seq模型,输入full history效果更好,这点和 [2021-ACL] Dual Slot Selector via Local Reliability Verification for Dialogue State Tracking 中提出的观点相反。缺点:没有开源!!!
- [2021-ACL] Dual Slot Selector via Local Reliability Verification for Dialogue State Tracking, arXiv ✅
小样本
- [2021-NAACL] Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking, arXiv github ✅
- 作者对不同slot进行了分类,然后提出使用 Slot Type Informed Description 来捕捉不同 slots 之间共享的信息,把context和 slot description concat到一起输入encoder-decoder生成value,作者用不同的 slot description 进行了实验,其所提出的Slot Type 形式如下
[prefix] [slot type] of [slot] of the domain,比如slot=hotel-stars,则slot description=numbers of stars of the hotel,作者认为 explicit information about the target value (i.e., slot type) is important in the low resource condition,这种 type 知识可以在不同slot之间迁移 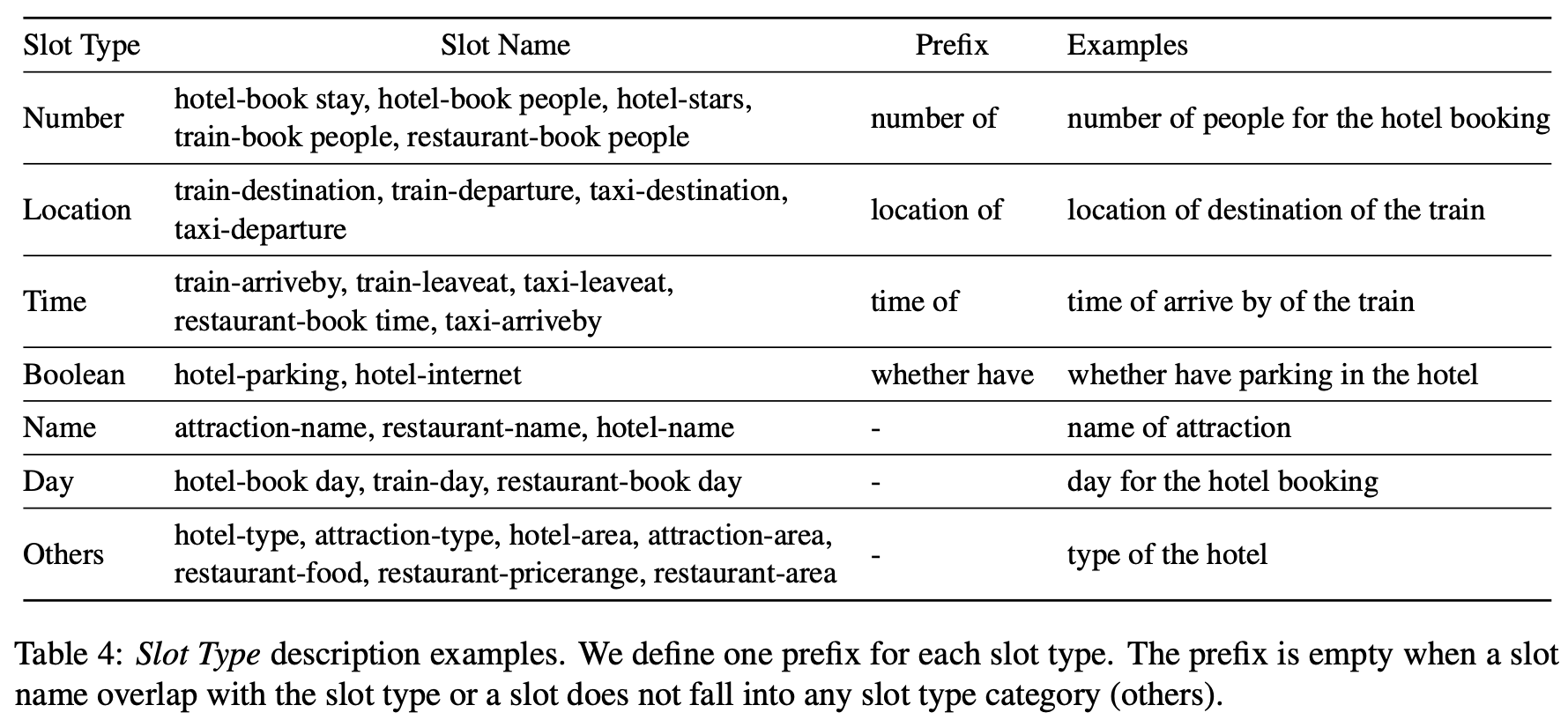

- 作者对不同slot进行了分类,然后提出使用 Slot Type Informed Description 来捕捉不同 slots 之间共享的信息,把context和 slot description concat到一起输入encoder-decoder生成value,作者用不同的 slot description 进行了实验,其所提出的Slot Type 形式如下
- [EMNLP-2021] Zero-Shot Dialogue State Tracking via Cross-Task Transfer, arXiv github ✅
- 作者的动机是说在QA中,每一个question都可以被认为是一个待填的slot,而DST数据集的slots非常有限,multiwoz有8000+对话,110000+轮,但是只有30个不到的slots,这样的话Zero-Shot时很难 generalize 到其他类型的 slot,而QA数据集有50w+问题,可以提高泛化能力
- 用QA任务训练模型,QA分为 Extrative Question 和 Multi-Choice Question,用 encoder-decoder 架构生成 answer,在DST Zero Shot阶段把所有slot建模为一个问题,如 “what is the
of the that user wants?” 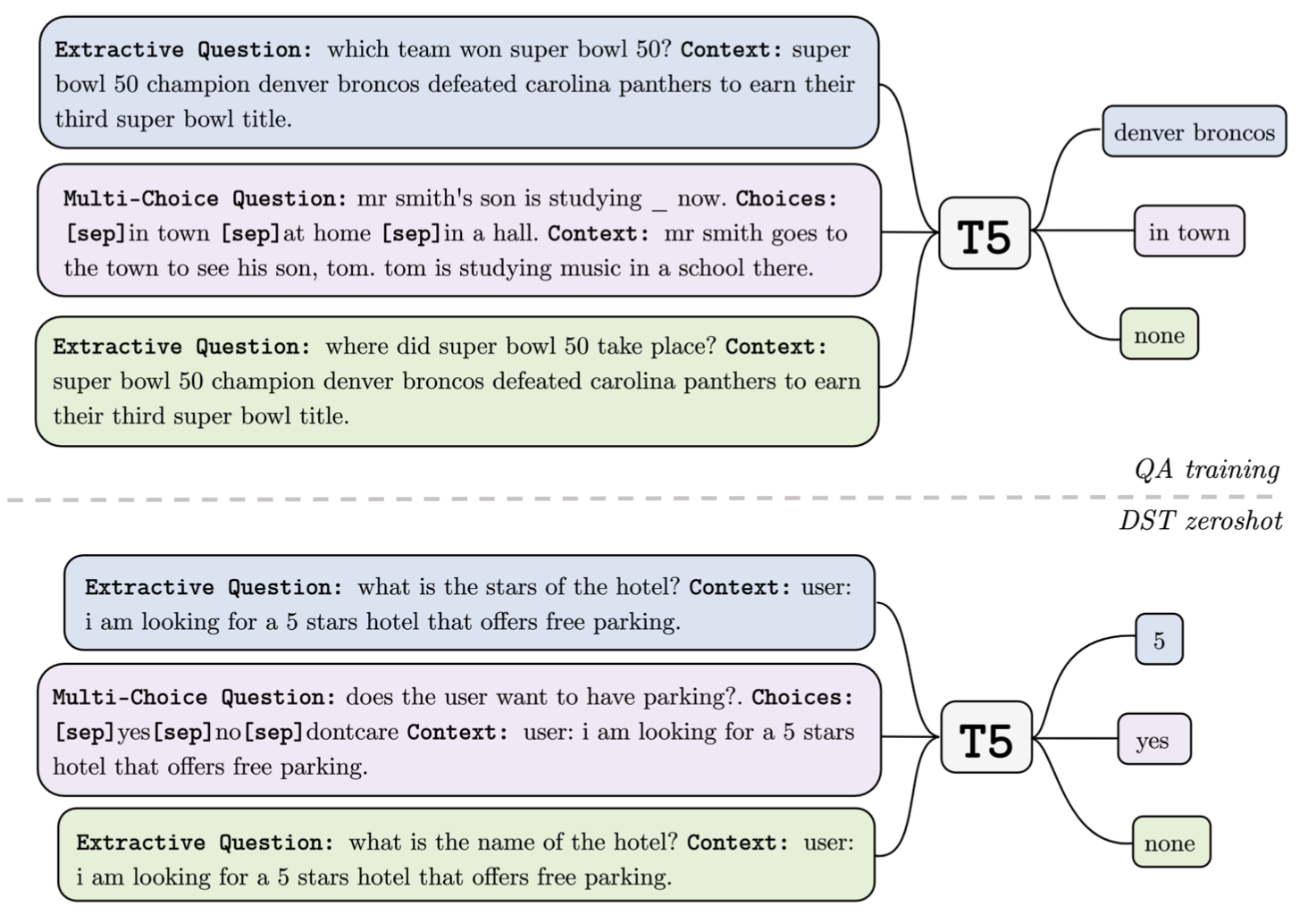
- 为了让模型学会识别unanswerable question(给slot预测none),设计了两种方式构建负样本,一种是Negative Question Sampling,即随机采样出和Context无关的Question,这种Out-of-Context的QA对应Out-of-Domain的DST,另一种是Context Truncation, 即把QA中包含answer的Context给截掉,这种针对DST中的In-Domain-Unmentioned,但是消融实验表明CT的帮助并不大,而NQS却影响非常大,作者解释NQS有效是因为unanswerable问题太多了,所以在QA中加这个和DST任务的gap比较小
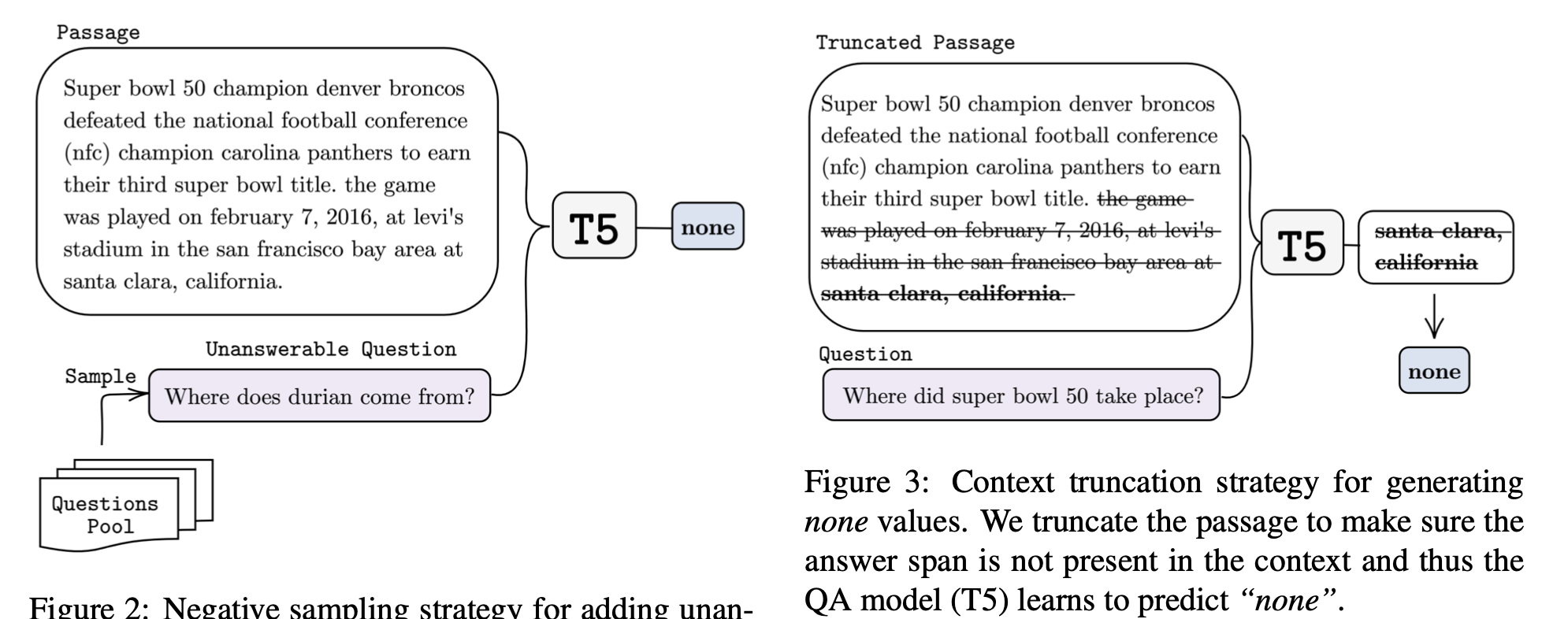
- 我的思考: CT和NQS都是属于unanswerable,但是NQS采样的问题都是和context无关的,CT只是截掉了答案,为什么CT效果不是更好呢?它毕竟是Context-Related的,相比NQS更不容易分辨出是unanswerable
- 作者通过 error analysis 发现79.79%的错误来自于slot gate prediction(whether the slot is unanswerable or not),只有20.21%的错误是 slot value 预测错了,两种典型错误是 slot value 还没被 user 确定就被模型填上了,另一种是 user 已经提到了slot value 而模型没有捕捉到,作者的Oracle Study也表明了 slot gate prediction accuracy 非常重要,zero shot on multiwoz 能从35.77%提到56.06%
开放域对话
- Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation, ACM MM, 2021, arXiv ✅
- 2021-10-10组会报告
- Learning from Perturbations: Diverse and Informative Dialogue Generation with Inverse Adversarial Training, ACL, 2021, arXiv ✅
- 扰乱context X 得到 X’,然后 condition on X 和 X’ 分别生成回复 Y 和 Y’,Y 的概率相比 Y’ 越大越好,没什么意思,不知道这怎么都能中
- Towards Quantifiable Dialogue Coherence Evaluation, ACL, 2021, arXiv ✅
- 提出了一个新的 dialogue coherence 评估模型,用了一个多层次的打分loss(3个level,level越高的response越coherent,模型给分也要越高),加上知识蒸馏和对其的正则loss防止fine-tune时灾难性遗忘,实验效果显示相比于其他自动评估指标,跟人工标注的打分相关系数更高。
- I like fish, especially dolphins: Addressing Contradictions in Dialogue Modeling, ACL, 2021, arXiv ✅
- 提出了一个新的数据集来做dialogue contradiction detection,比用NLI数据集好很多;提了一个structured utterance-based approach来检测对话冲突,就是把要检测的这句话和该speaker之前说过的话组成pair,计算分数,取最高分的那个做输出。
- NEURAL GENERATION OF OPEN-ENDED TEXT AND DIALOGUE, Abigail See PhD Thesis, 2021, PDF ✅
- BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data, ACL, 2021, arXiv ✅
- Towards Emotional Support Dialog Systems, ACL, 2021, arXiv ✅
- Towards a Human-like Open-Domain Chatbot, Google Brain, 2020, arXiv ✅
- 提出了一个人工评估指标叫 Sensiblenes Specificity Average(SSA),实验显示SSA和Perplexity之间有很强正相关,两个我觉得作者提出的比较重要的观点:1. beam-search decoding 会生成重复和无趣的回复,当模型的困惑度足够低时,单纯地使用 sample-and-rerank 就已经足够生成多样的、内容丰富的回复,sample-and-rerank 指在温度T下采样N个回复,然后根据生成的概率 rerank, 选择概率最高的那个回复;2. 在非常大的社交语料上的 perplexity 可以作为一个人工评估指标(human-likeness, sensibleness and specificity)的代表,这意味着仅仅需要最小化大规模社交语料上的 perplexity 就可以获得一个人性化的开放域对话模型
- Recipes for building an open-domain chatbot, FAIR, 2020, arXiv
问答系统
- xMoCo: Cross Momentum Contrastive Learning for Open-Domain Question Answering, ACL, 2021, PDF ✅
- 使用了两套fast和slow encoder,分别对问题和文章编码,然后优化fast question与slow passage,和slow question和fast passge,fast encoder编码的question与passage不直接互相影响,而是通过对方的slow encoder影响,而slow encoder依赖对应的fast encoder进行更新
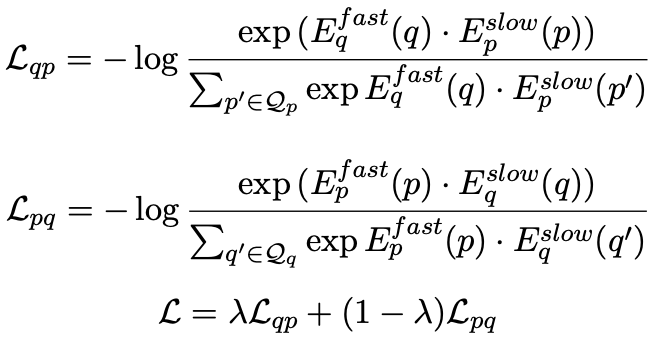
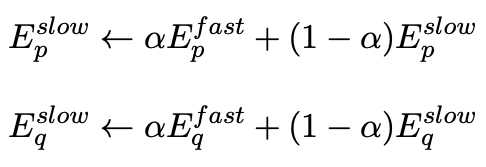
- A Semantic-based Method for Unsupervised Commonsense Question Answering, ACL, 2021, arXiv ✅
- 提出了一个基于语义的无监督QA方法,不同于之前的方法利用预训练语言模型去计算$P(answer ~choice \vert question)$,因为作者认为生成answer的概率很容易被一些因素影响,比如词频、句子结构(比如换个同义词或者换成被动句式打分就低了),所以作者希望是基于answer的语义,而不是answer这句话本身,作者先通过rewrite的方式,让PLM基于question生成多个回复,这些回复叫做supporters,然后用一个句子语义相似度模型,比如SBERT等,针对每一个answer choice,计算所有supporters和它的相似度并求和,得到该answer choice的得分,最终得分最高的answer choice被选择。
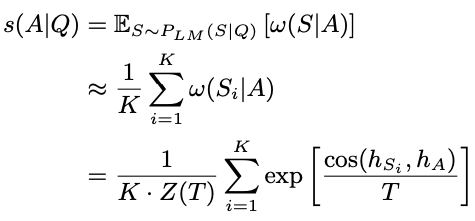
Transformers
- A Survey of Transformers arXiv
- Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Document Modeling, ACL, 2021, short, arXiv ✅
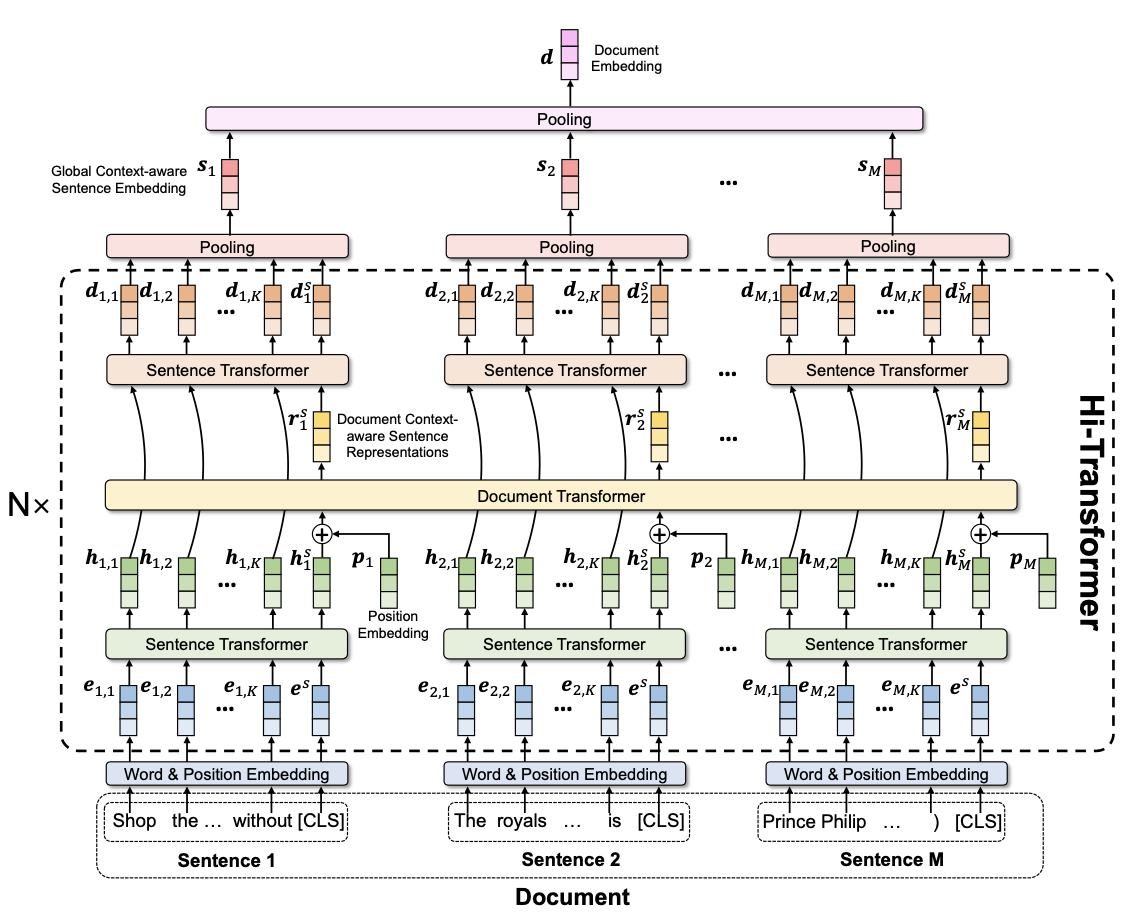
- 第一步:先用类sbert模型获得文档中每个句子的句子表征([CLS]的embedding),第二步:再把句子表征当word,经过一个transformer得到看到整个文档全局信息的表征,第三步:把第二步的表征当成第一步的[CLS]再来一次,得到最终的表征,进行Hierarchical Pooling得到最终的文档表征。个人认为是刮痧。
文本生成
#TODO Contrastive Learning with Adversarial Perturbations for Conditional Text Generation, ICLR, 2021
- 利用对比学习缓解文本生成中的曝光偏差问题, 文章探索了一种利用对比学习来缓解曝光偏差的方法,借助梯度,在表示空间对解码端表示进行修改,从而生成高难度的正例和负例用于对比学习
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models, Ashwin K Vijayakumar et al. arxiv, 2016 PDF arXiv (Citations 219) ✅
提出diverse beam search,候选句的分数不但与概率有关,还与其他已经生成的句子的相似度有关。解读博客
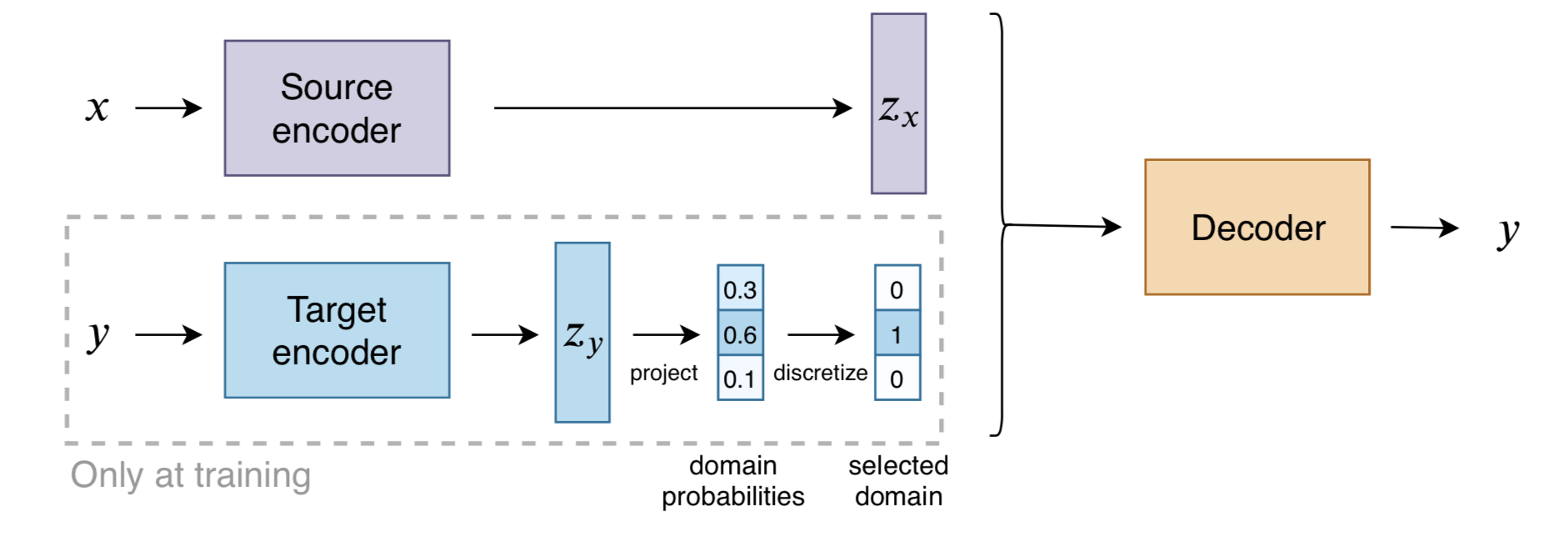
Target Conditioning for One-to-Many Generation, Marie-Anne Lachaux et al. EMNLP-findings, 2020 PDF arXiv (Citations 0) ✅
这篇工作借鉴了 discrete autoencoders 的思路,提出将一个 discrete target encoder 引入到翻译模型中,方便将每一个目标语句关联到对应的 variable 或者 domain。其中每一个 domain 对应一个 embedding,这样在测试阶段可以根据每个 domain embedding 来生成多样性的翻译。并且这种离散化的表示方式允许无监督地方式来改变翻译的 domain 信息。周报2021.04.25中解读
Seq2Seq中Exposure Bias现象的浅析与对策 by 苏剑林 ✅
- 缓解teacher forcing造成的exposure bias问题,作者提出了两个简单的方法:1. 构建负样本,从target中随机抽取单词并替换decoder使用teacher forcing时的输入词。2. 对抗训练(梯度惩罚)
从语言模型到Seq2Seq:Transformer如戏,全靠Mask by 苏剑林 ✅
Data Distillation for Controlling Specificity in Dialogue Generation, Jiwei Li et al. arxiv, 2017 PDF arXiv (Citations 18) ✅
每轮把模型生成的最频繁的句子选出来,然后和训练集的句子计算相似度,去掉这些相似度最高的句子

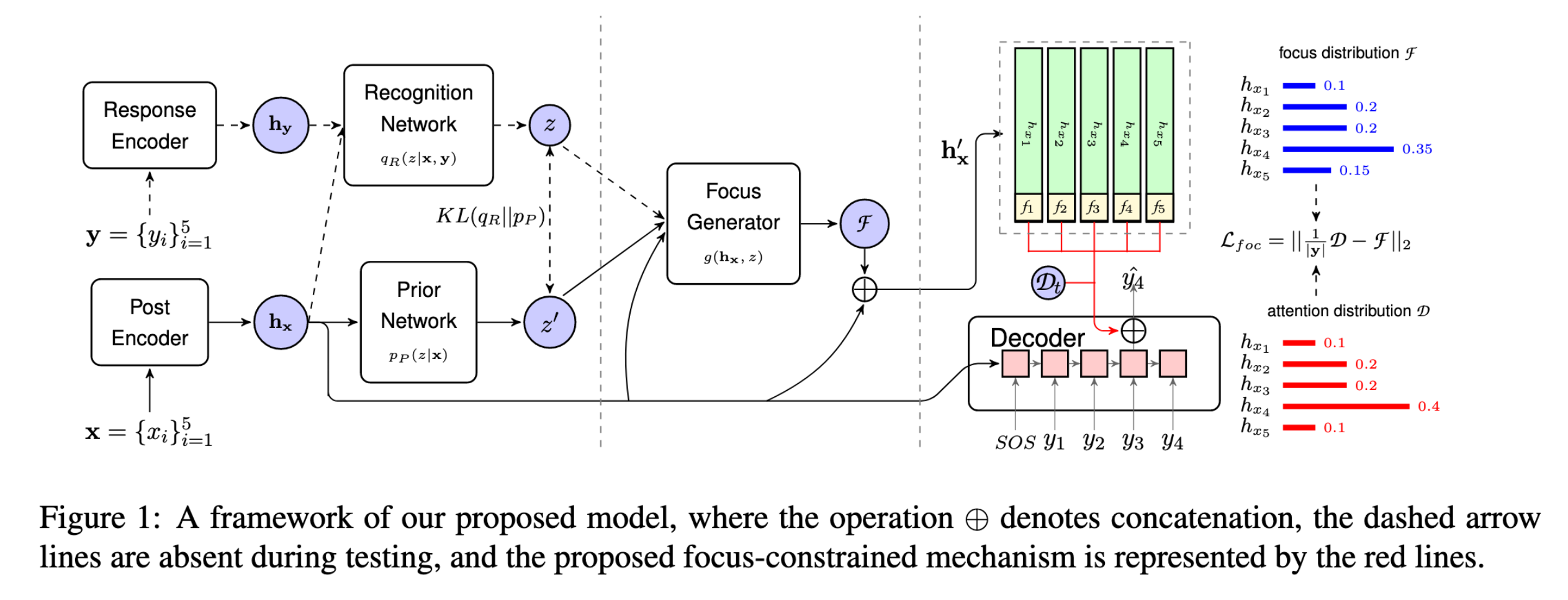
Focus-Constrained Attention Mechanism for CVAE-based Response Generation, Zhi Cui et al. EMNLP-findings, 2020 PDF arXiv (Citations 0) ✅
- 把隐变量z和encoder output做attention得到focus,然后把focus和encoder output concat起来输入decoder,并在每一步解码求attention时使用;引入coverage vector,本质是解码时每一步的attention权重累加;设计focus constraint,本质是让focus和coverage vector欧几里得距离最小。
https://www.aclweb.org/anthology/P17-1061.pdf Learning Discourse-level Diversity for Neural Dialog Models using Conditional Variational Autoencoders
https://arxiv.org/pdf/1606.07947.pdf Sequence-Level Knowledge Distillation
词表征
- NLP的巨人肩膀,梳理了从2003年的NNLM开始,到今天的BERT、GPT这些语言表征学习的发展历程,探究NLP或NLU的历史,也可以说同样也是探究文本如何更有效表征的历史。深度好文,推荐!✅
有监督
- Learned in Translation: Contextualized Word Vectors, 2017, arXiv, (Citations 750)
- CoVe,算是ELMo的前辈,首先用一个Encoder-Decoder框架在机器翻译的训练语料上进行预训练,之后用训练好的模型,只取其中的Embedding层和Encoder层,同时在一个新的任务上设计一个task-specific模型,然后将原先预训练好的Embedding层和Encoder层的输出作为这个task-specific模型的输入,最终在新的任务场景下进行训练。和诸如Skip-Thoughts等方法有所不同的是,CoVe更侧重于如何将现有数据上预训练得到的表征迁移到新任务场景中,而之前的句子级任务中大多数都只把迁移过程当做一个评估他们表征效果的手段(比如STS和SentEval),因此观念上有所不同。
无监督
- Deep contextualized word representations, NAACL, 2018, arXiv, (Citations 7706)
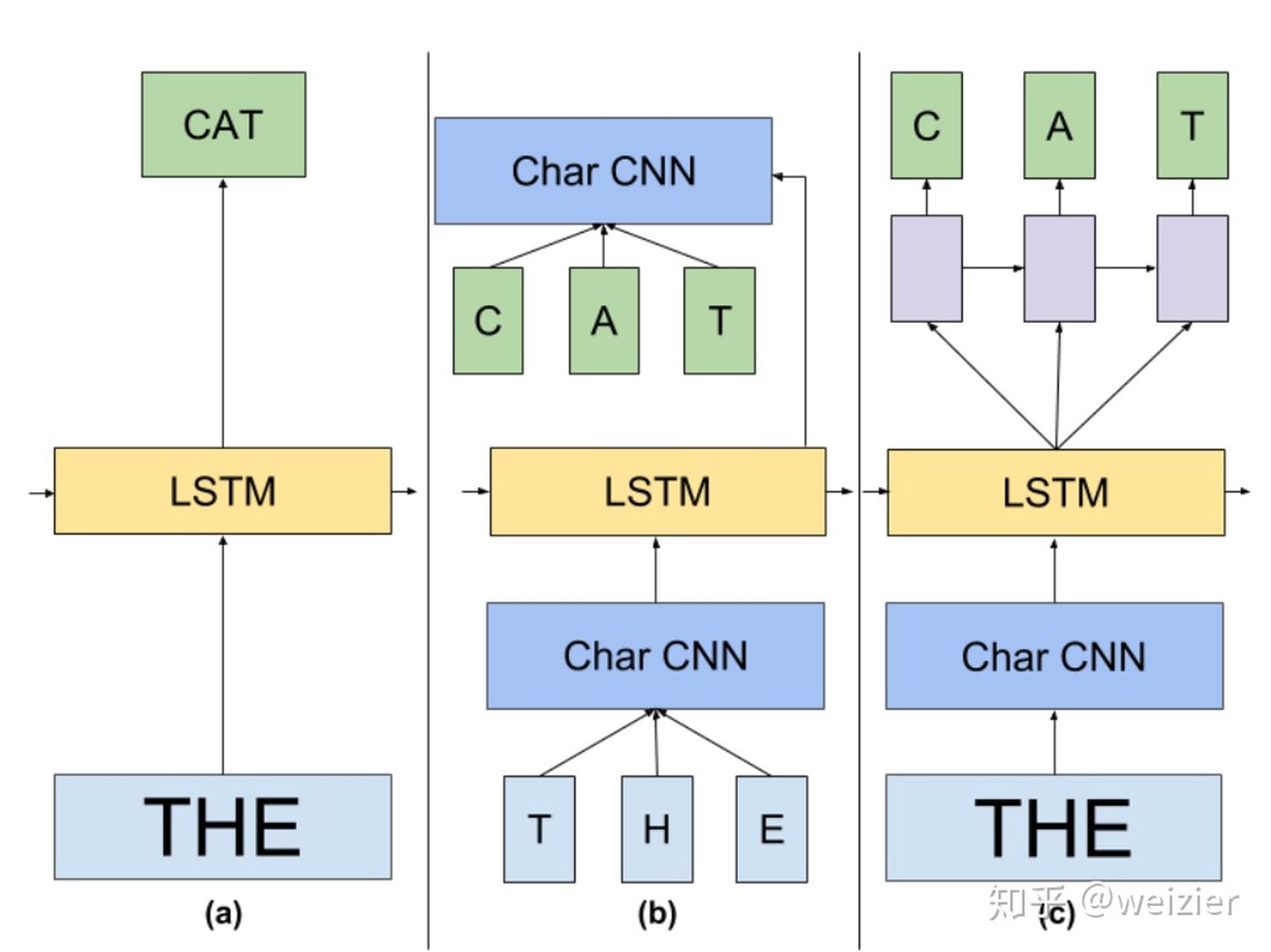
- ELMo借鉴了2016年Google Brain的Rafal Jozefowicz等人发表的一篇论文《Exploring the Limits of Language Modeling》,其主要改进在于输入层和输出层不再是word,而是变为了一个 char-based CNN 结构,ELMo在输入层和输出层考虑了使用同样的这种结构,这样不用再维护一个V*h大的word embedding,还可以解决OOV问题,只需要维护一个26*h的char embedding和CNN,CNN对所有单词都是共享参数的,所以大大减少了参数量,在预测阶段,CNN对于每一个词向量的计算可以预先做好(就是把所有单词的表征CNN(t_k)都给计算出来),更能够减轻inference阶段的计算压力
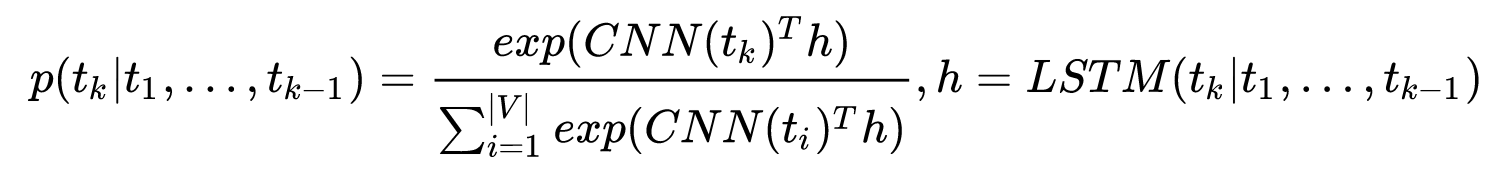
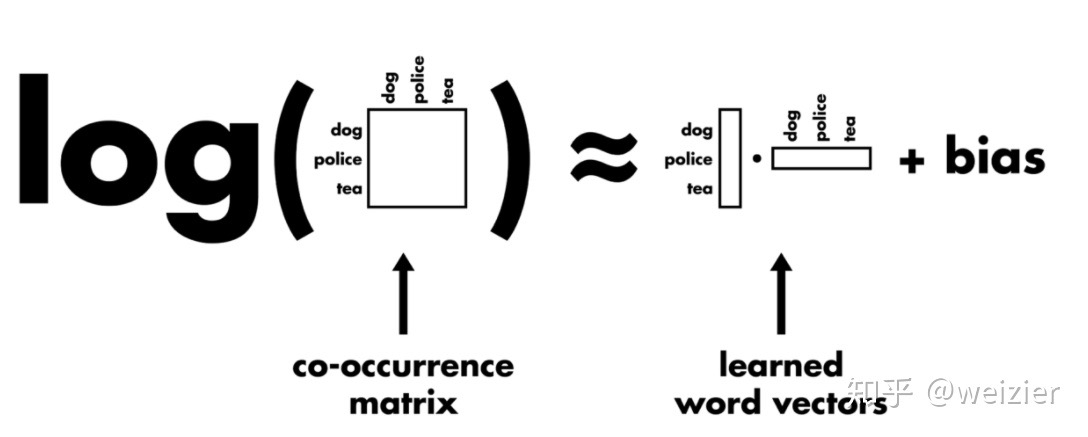
- GloVe,$X_{ij}$是两个词i和j在某个窗口大小中的共现频率,是一个权重系数,主要目的是共现越多的pair对于目标函数贡献应该越大,但是又不能无限制增大,所以对共现频率过于大的pair限定最大值,以防训练的时候被这些频率过大的pair主导了整个目标函数,两个b值是两个偏置项,那么剩下的$\left(w_{i}^{T} w_{j}-\log X_{i j}\right)^{2}$其实就是一个普通的均方误差函数,$w_i$ 是当前词的向量,$w_j$对应的是与其在同一个窗口中出现的共现词的词向量,两者的向量点乘要去尽量拟合它们共现频率的对数值。从直观上理解,如果两个词共现频率越高,那么其对数值当然也越高,因而算法要求二者词向量的点乘也越大,而二个词向量的点乘越大,其实包含了两层含义:第一,要求各自词向量的模越大,通常来说,除去频率非常高的词(比如停用词),对于有明确语义的词来说,它们的词向量模长会随着词频增大而增大(因为词频高所以概率score大,所以应该模长大),因此两个词共现频率越大,要求各自词向量模长越大是有直觉意义的,比如“魑魅魍魉”假如能被拆分成两个词,那么“魑魅”和“魍魉”这两个词的共现频率相比““魑魅”和其他词的共现频率要大得多,对应到“魑魅”的词向量,便会倾向于在某个词向量维度上持续更新,进而使得它的模长也会比较偏大;第二,要求这两个词向量的夹角越小,这也是符合直觉的,因为出现在同一个语境下频率越大,说明这两个词的语义越接近,因而词向量的夹角也偏向于越小。(GloVe考虑到了对距离较远的词对做相应的惩罚,这一点是怎么做的还未了解,距离远是指按字典序排离得很远吗?)
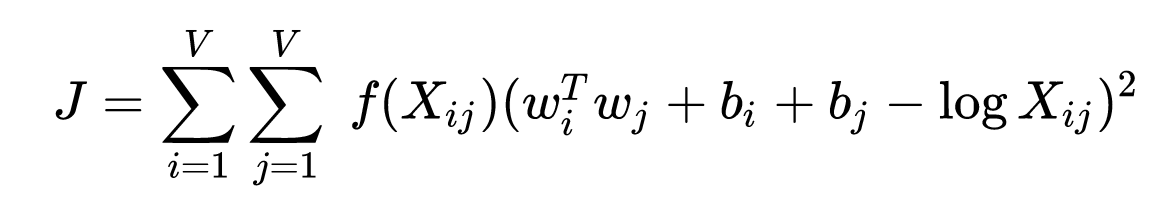
句子表征
有监督
- Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning, ICLR 2018, arXiv (Citations 264)
- 提出了利用四种不同的监督任务来联合学习句子的表征,这四种任务分别是:Natural Language Inference, Skip-thougts, Neural Machine Translation 以及 Constituency Parsing。作者认为,通用的句子表征应该通过侧重点不同的任务来联合学习到,而不是只有一个特定任务来学习句子表征。所以模型将同时在多个任务和多个数据源上进行训练,并且共享句子表征。先用联合学习的方法在上述四个任务上进行训练,训练结束后,将模型参数冻结,只作为特征提取器提取句子表征,然后直接接上全连接层作为分类器,在新的分类任务上只训练分类器。作者发现很多任务上简单分类器都要超过当时的最好结果,并且他们还发现联合训练中不同的任务对于句子表征中的不同方面有不同的贡献。
- Parameter-free Sentence Embedding via Orthogonal Basis, EMNLP, 2019, arXiv (Citations 15) ✅
- SBERT-WK: A Sentence Embedding Method by Dissecting BERT-based Word Models, 2020, arXiv (Citations 30) ✅
- 上一篇论文是用在静态词向量,这篇用在BERT这种contextual embedding
- Supervised Learning of Universal Sentence Representations from Natural Language Inference Data, EMNLP, 2018, arXiv (Citations 1418) ✅
- Universal Sentence Encoder, EMNLP, 2018 arXiv (Citations 499) ✅
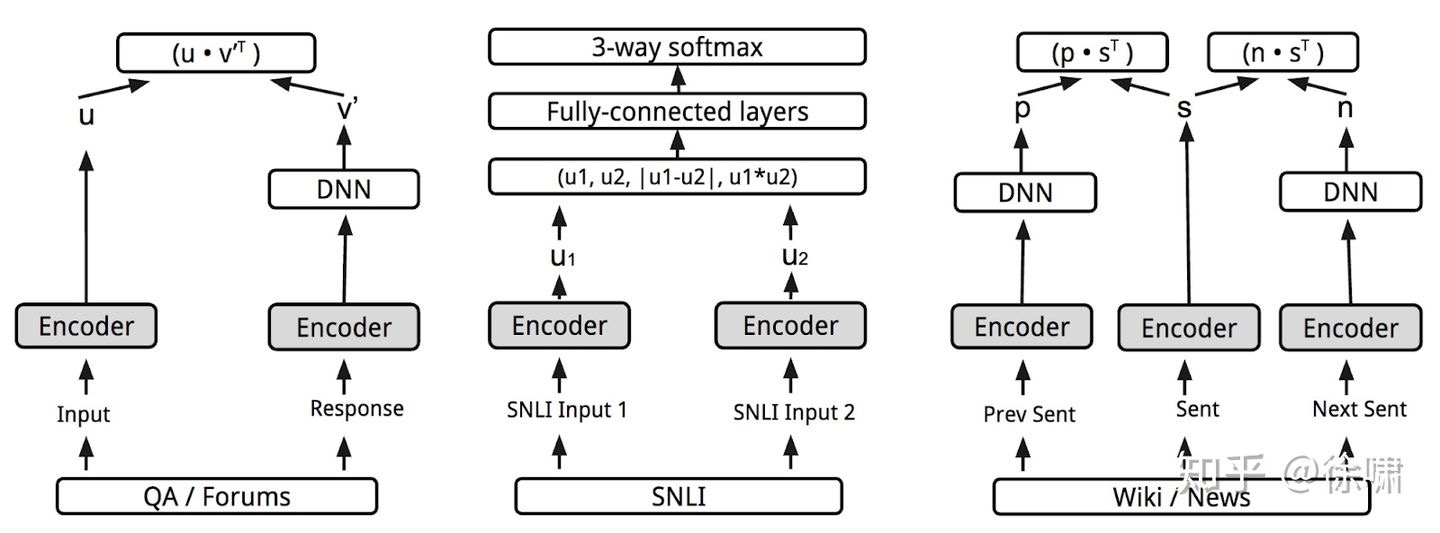
- 综合利用无监督训练数据和有监督训练数据,进行多任务训练,从而学习一个通用的句子编码器。无监督训练数据包括问答(QA)、维基百科和网页新闻等,有监督训练数据为SNLI。多任务模型设计如下图所示,其中灰色的 encoder 为共享参数的句子编码器。共享编码器使得模型训练时间大大减少,同时还能保证各类迁移学习任务的性能,力求为尽可能多的应用提供一种通用的句子编码器。
无监督
#TODO ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
#TODO Smoothed Contrastive Learning for Unsupervised Sentence Embedding
An efficient framework for learning sentence representations, ICLR, 2018, arXiv, (Citations 291) ✅
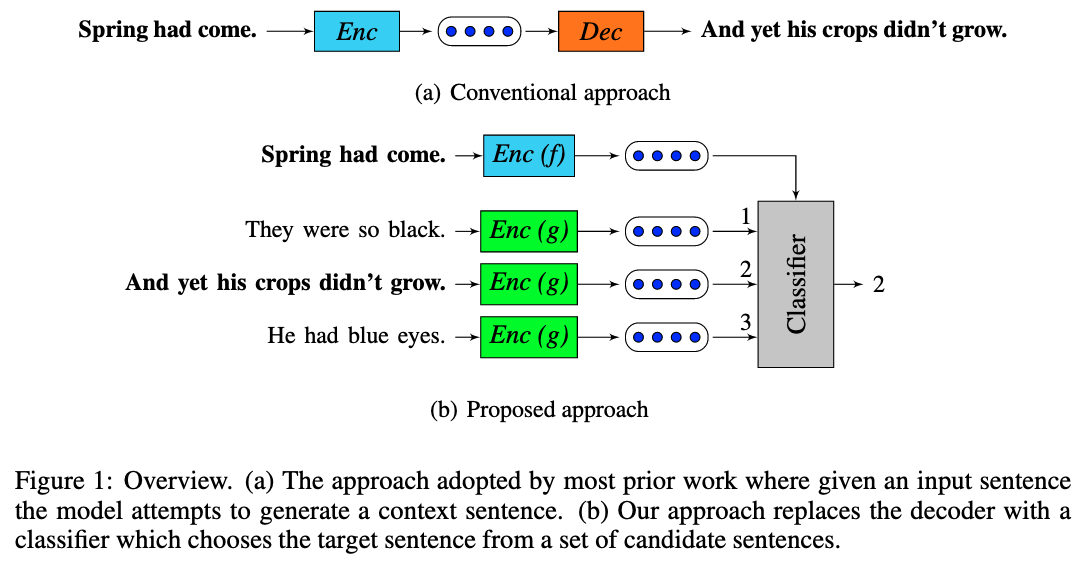
- Use the meaning of the current sentence to predict the meanings of adjacent sentences, where meaning is represented by an embedding of the sentence computed from an encoding function. Viewing generation as choosing a sentence from all possible sentences, this can be seen as a discriminative approximation to the generation problem. At test time, for a given sentence s, we consider its representation to be the concatenation of the outputs of the two encoders [f(s) g(s)]. 用给定的句子去预测候选的一组句子是否为其的毗邻句,把生成任务转为从所有可能的句子里选出真实的句子,用判别的方式去近似生成问题。很有对比学习的感觉,测试时用两个encoder f和g的concat作为句子向量
A Simple but Tough-to-Beat Baseline for Sentence Embeddings, ICLR, 2017, OpenReview (Citations 948) ✅
- 本质是一个词袋模型,以平滑倒词频 (smooth inverse frequency, SIF) 作为权重对词向量进行加权平均得到句子向量,即认为频率越低的词在在句子中的重要性更大。最后令每个句子向量都减去其在所有句子向量组成的矩阵的第一个主成分上的投影,即抹去所有句子的共有信息,这样可以增大每个句子向量之间的距离。

Bootstrapped Unsupervised Sentence Representation Learning, Yan Zhang, ACL, 2021, ACL, github还没开源 ✅
- 把BYOL那一套照抄到了NLP领域
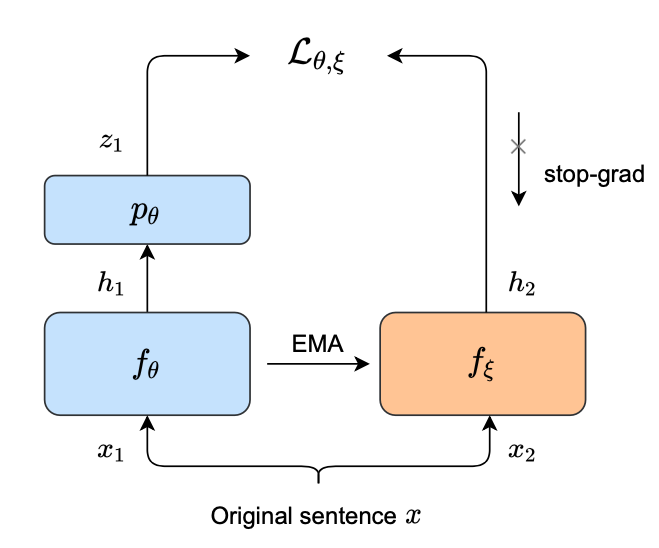
An Unsupervised Sentence Embedding Method by Mutual Information Maximization, Yan Zhang, EMNLP, 2020, arXiv, github (Citations 10) ✅
在BERT上面堆几个window size不同(1,3,5)的1D-CNN,然后把不同window size的特征concat起来作为token-level local representation $\mathcal{F}_{\theta}^{(i)}(\mathbf{x})$,对句子里所有的token表征做pooling后得到sentence-level global representation $\mathcal{E}_{\theta}(\mathbf{x})$,最大化同一句子全局表征和局部表征的琴生-香侬估计(Jensen-Shannon MI estimator),如下式,sp是softplus函数$sp(z)=\log(1+e^z)$,性能在STS和SentEval task是当时无监督方法里最好的,媲美有监督的InferSent,但不如USE和SBERT,优点是不需要标注数据,可以在各种task-specific的数据集上训练,指出了SBERT这类有监督模型在NLI这种非task-specific数据集上训练后,迁移到其他domain的数据集上时不适应,效果非常差
#TODO 如果把顶层的CNN换成现在的vision transformer,会不会更好?
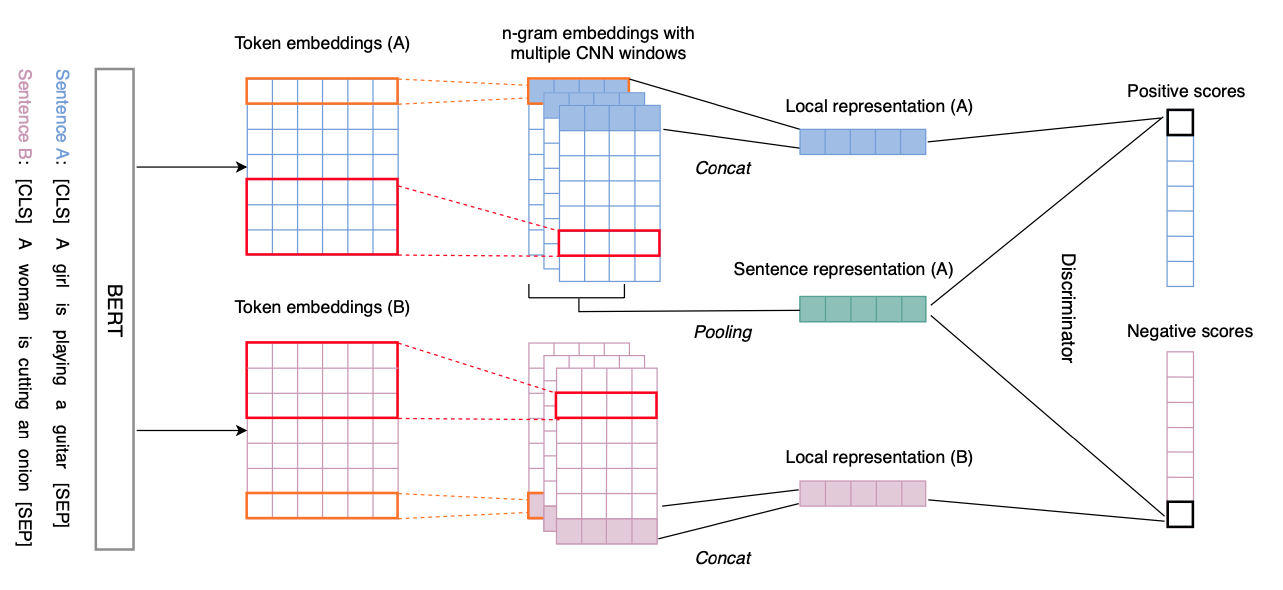
Self-training Improves Pre-training for Natural Language Understanding, NAACL, 2021, arXiv (Citations 25) ✅
- 准备一个非常非常大的句子集,包含上亿个的句子,然后用一个训练好的句子编码器(这个句子编码器是为语义相似度搜索专门训练的,用的triplet loss)去编码下游任务的训练集,根据class分类,把同一class的句子表征取平均作为query,然后到句子集里召回最相似的句子,把这些句子给一个在下游任务上fine-tune过的大型预训练teacher模型打上软标签,作为新的in-domain task-specific的人造数据集,最终用一个参数量更少的student模型在这些人造数据集上训练得到最终模型,这种self-training方式可以作为pre-training的补充,能进一步提升性能,总体上用到了句子表征编码器、知识蒸馏,github有人问作者这本质和远程监督有什么区别,未获得回复
Skip-Thought Vectors, NIPS 2015 arXiv (Citations 2232) ✅
- 用一个基本的encoder-decoder模型,使用小说集作为语料,假设有三句连贯的句子,用编码器把中间那句编码为一个向量,然后用两个解码器分别解码生成它的上句和下句。使用时冻结参数,用编码器获得句子表征,然后在它上面加个线性分类器,就可以训练后做分类了
- 词表扩充,可以使用一个大型的预训练词向量,文中用了CBOW,用一个矩阵W把CBOW的embedding映射到模型的embedding,最小化L2损失得到W,之后在使用中遇到训练时没有的单词就用W对其进行映射
CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding, Dong Wang et al. ACL, 2021 arXiv (Citations 0) ✅
Self Supervised Representation Learning in NLP 总结了11种nlp任务用到的自监督方法,比如CBOW、skip-gram、MLM、NSP等等 ✅
Self-Guided Contrastive Learning for BERT Sentence Representations, Taeuk Kim et al. ACL, 2021 arXiv (Citations 0) ✅
SimCSE: Simple Contrastive Learning of Sentence Embeddings arXiv github (Citations 3) ✅
- 目前semantic textual similarity tasks的 SOTA,支持无监督和有监督,使用对比学习,正例对只使用了两个不同的dropout mask
DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations ACL,2021, arXiv github (Citations 23) ✅
- 对每一篇文档,随机采样几个span作为anchor samples,对于每个anchor sample从同一个文档里采样几个span作为positive samples(span的长度服从beta分布,anchor偏长,positive偏短),用transformer模型分别编码它们并做pooling得到句子表征,把几个positive samples求平均得到anchor sample的正例表征,使用NT-Xent loss函数
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Evaluating Models’ Local Decision Boundaries via Contrast Sets, AllenAI, EMNLP-findings 2020
CV
图片表征
- Learning deep representations by mutual information estimation and maximization, R Devon Hjelm, ICLR, 2019, arXiv, github (Citations 864) ✅
太难了没怎么看明白,作者指出仅仅是最大化模型输入的特征与输出的表征之间的互信息是不够的,相反,如果最大化输出表征与输入的局部区域(local region)特征之间的平均互信息,能够极大地提升表征的质量。作者表明DIM可以使用不同的MI估计方法,文中使用了三种:基于 DV representation、琴生香侬估计JSD、InfoNCE,作者发现JSD对负样本的数量不敏感,几乎不受负样本数量的影响,infoNCE效果随负样本数量提升而提升,DV 受到负样本数量的影响最大,但是随着负样本数量的增加,它们之间的差距会逐渐缩小。- 深度学习的互信息:无监督提取特征 by 苏剑林 ✅
- 对 Deep InfoMax(DIM)的理解 知乎博客,大体是翻译了原论文加入作者的一些理解,翻译得比较好,global infomax和local infomax的流程也梳理得比较清晰 ✅
- DIM:通过最大化互信息来学习深度表征 知乎博客,作者从最大化互信息和先验KL散度约束的目标函数出发,中间将KL散度换成局部变分法推导的JS散度,最终推导出结果等价于NCE,内容比较像苏剑林的博客 ✅
- 无监督学习: Kaiming一作 动量对比(MoCO)论文笔记 ✅
- Momentum Contrast for Unsupervised Visual Representation Learning arXiv (Citations 952)

- 无监督学习距离监督学习还有多远?Hinton组新作解读 ✅
- #TODO Learning deep representations by mutual information estimation and maximization
- #TODO A theoretical analysis of contrastive unsupervised representation learning arXiv
- #TODO NIPS2020: What Makes for Good Views for Contrastive Learning?
- #TODO ICLR2021: Self-Supervised Learning From a Multi-View Perspective
- #TODO ICLR2021: FAIRFIL: Contrastive Neural Debiasing Method For Pretrained Text Encoders
重参数化
- Categorical Reparameterization with Gumbel-Softmax, Eric Jang et al. ICLR, 2017 PDF arXiv (Citations 1881), Jang’s blog ✅
Gumbel Max和Gumbel Softmax详细推导参考漫谈重参数:从正态分布到Gumbel Softmax by 苏剑林,英文博客,重参数化的作用简易理解参考下面来自知乎回答的评论区中Towser的回复 ✅
#TODO https://arxiv.org/pdf/1308.3432.pdf Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
- #TODO https://arxiv.org/abs/1611.00712 The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
知识蒸馏
- Distilling the Knowledge in a Neural Network, Hinton et al. arxiv, 2015 PDF arXiv (Citations 6051) ✅
VAE
- VQ-VAE的简明介绍:量子化自编码器 ✅ 因为没看过pixel-cnn导致不能完全看懂,其中提到的stop gradient方法可以为很多函数自己定义梯度,实用价值需要具体任务具体分析,有参考启发意义。
- #TODO vae-tutorial
对抗训练
- 对抗训练浅谈:意义、方法和思考 by 苏剑林 ✅
- 快速梯度等价于梯度惩罚,快速梯度是给输入x加上$\Delta x=\epsilon \nabla_{x} L(x, y ; \theta)$,梯度惩罚是给loss加上$\frac{1}{2} \epsilon\left|\nabla_{x} L(x, y ; \theta)\right|^{2}$
- 功守道:NLP中的对抗训练 + PyTorch实现 by 富邦
- #TODO https://arxiv.org/abs/1312.6199 Intriguing properties of neural networks (Citations 6912)
- #TODO https://arxiv.org/abs/1706.06083 Towards Deep Learning Models Resistant to Adversarial Attacks (Citations 3192)
- #TODO https://arxiv.org/abs/1412.6572 Explaining and Harnessing Adversarial Examples (Citations 7566)
- #TODO https://arxiv.org/abs/1605.07725 Adversarial Training Methods for Semi-Supervised Text Classification (Citations 439)
- #TODO https://arxiv.org/abs/1711.09404 Improving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing their Input Gradients (Citations 278)
数学相关
#TODO 《让人惊叹的Johnson–Lindenstrauss引理:理论篇》
- 在这篇文章中,我们介绍了Johnson–Lindenstrauss引理(JL引理),它是关于降维的一个重要而奇妙的结论,是高维空间的不同寻常之处的重要体现之一。它告诉我们“只需要O(logN)维空间就可以塞下N个向量”,使得原本高维空间中的检索问题可以降低到O(logN)维空间中。
Hierachical Softmax
- 这是对full softmax的一种优化手段,Hierachical Softmax的基本思想就是首先将词典中的每个词按照词频大小构建出一棵Huffman树,保证词频较大的词处于相对比较浅的层,词频较低的词相应的处于Huffman树较深层的叶子节点,每一个词都处于这棵Huffman树上的某个叶子节点,这样将原本的一个|V|分类问题变成了$\log|V|$ 次的二分类问题。做法简单来说就是,原先要计算$P(w_t|c_t)$ 的时候,因为使用的是普通的softmax,势必要求词典中的每一个词的概率大小,为了减少这一步的计算量,在Hierachical Softmax中,同样是计算当前词$w_t$在其上下文中的概率大小,只需要把它变成在Huffman树中的路径预测问题就可以了,因为当前词$w_t$在Huffman树中对应到一条路径,这条路径由这棵二叉树中从根节点开始,经过一系列中间的父节点,最终到达当前这个词的叶子节点而组成,那么在每一个父节点上,都对应的是一个二分类问题(本质上就是一个LR分类器),而Huffman树的构造过程保证了树的深度为$\log|V|$,所以也就只需要做$\log|V|$次二分类便可以求得的$P(w_t|c_t)$大小,这相比原来|V|次的计算量,已经大大减小了。
寻求一个光滑的最大值函数 by 苏剑林 ✅
#TODO On Variational Bounds of Mutual Information arXiv (Citations 164)
自监督和无监督学习
对比学习
#TODO On mutual information maximization for representation learning, ICLR, 2020, arXiv
#TODO Mine: mutual information neural estimation, ICML, 2018
#TODO Self-supervised Learning: Generative or Contrastive arXiv (Citations 65)
#TODO Debiased Contrastive Learning, NIPS, 2020
#TODO Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data
#TODO Learning representations by maximizing mutual information across views
#TODO A theoretical analysis of contrastive unsupervised representation learning, ICML
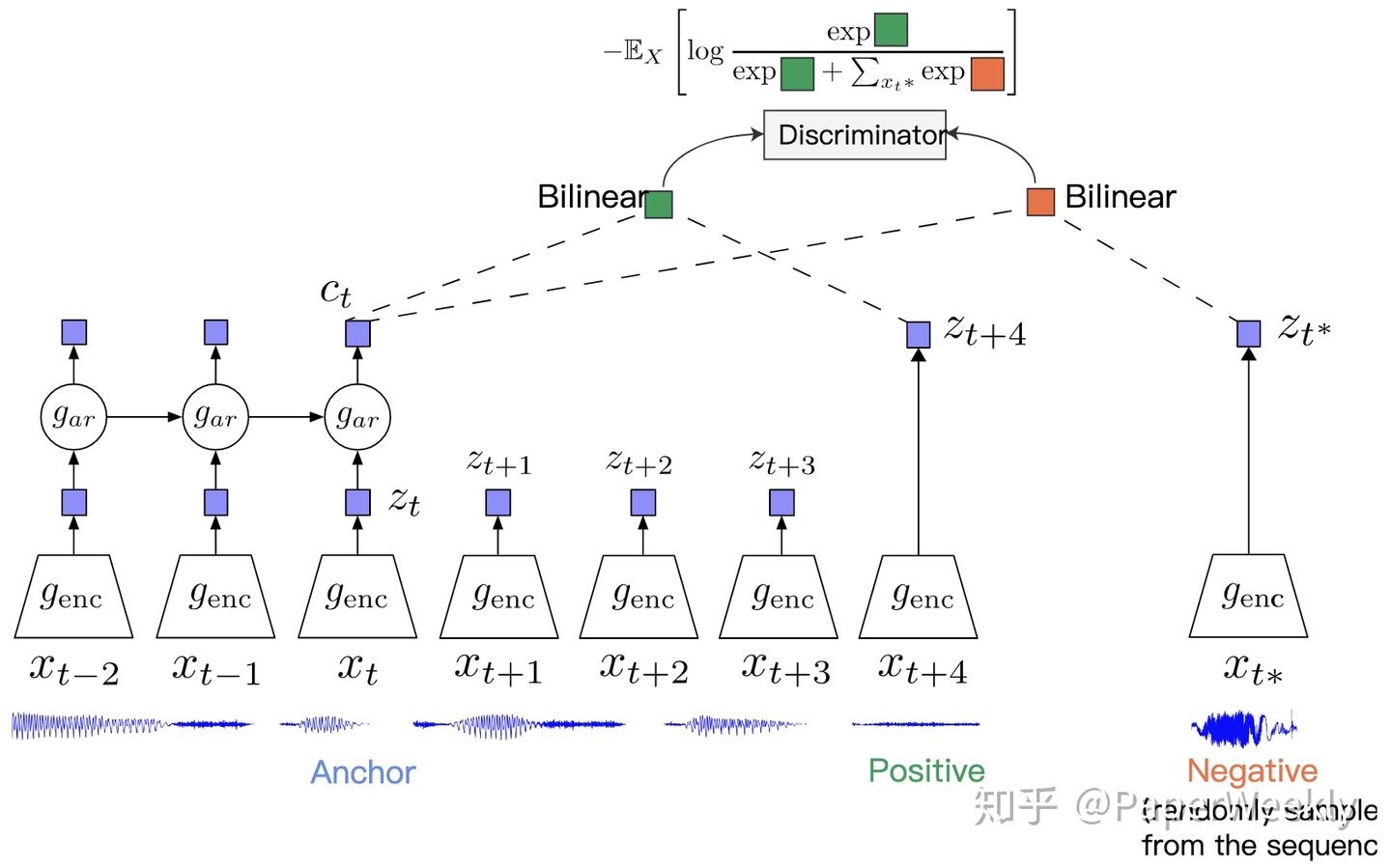
Representation Learning with Contrastive Predictive Coding arXiv (Citations 1078)
- 一定窗口内的$x_t$和$x_{t+k}$为positive pair,随机采样一个$x_{t*}$作负例,为了把历史的信息也加入进去,作者提出可以在编码器上面再叠一个自回归模型,比如rnn这种,把编码器的输出$z_t$当作输入,这样可以在表示$c_t$中融入时序信息,拿$c_t$来做对比学习,下游任务既可以用$c_t$也可以用$z_t$,又或者是二者的融合。
-
- 介绍了Contrastive loss、Triplet loss、Triplet center loss、N-pair loss(应该就是infoNCE)、Quadruplet loss、Lifted Structure loss
- N-pair loss中相似度D如果是向量点积,就等价于InfoNCE
捋一捋 NCE 公式推导比较详细,softmax中的分母计算量太大,NCE是是用一个二分类任务去逼近softmax的训练效果,推导证明了当k足够大时,采样k个负样本,NCE的目标函数和使用了softmax函数的最大似然是等价的。✅
一文梳理2020年大热的对比学习模型 by 李rumor ✅
Noise Contrastive Estimation 前世今生——从 NCE 到 InfoNCE ✅
InfoNCE中这个式子的意思是说给定条件c,在一堆例子X中发现$x_{pos}$是正例概率,那就应该是$x_{pos}$被当成正例的概率除以所有其他sample被当成正例的概率
Contrastive Representation Learning by lilian wen ✅
Hard Negative Mining,因为我们并不知道负样本的真实分布概率,因此采样时有可能采样到正样本作为了负样本,即false negative,导致bias,下面的概率公式是对这种bias做了debias Chuang et al., 2020

Understanding contrastive representation learning through alighment and uniformity on the hypersphere, Tongzhou Wang, ICML, 2020 arXiv (Citations 113) ✅
Understanding the behaviour of contrastive loss, Feng Wang, CVPR, 2021 arXiv (Citations 6) ✅
首先有
求梯度后可以得到
可以发现,如果$P_{i,i}=1$的时候,alignment就做到perfect了,而对于负例的梯度是与$P_{i,j}$正相关的,负例的相似度得分越大,梯度越大,也即对其的惩罚越大。对正例的梯度绝对值等于对所有负例的梯度之和。总结在2021.07.18的周报里,知乎解读博客,
如果太注重困难负样本则会破坏网络经过一定训练后已经学到的语义信息,这种情况在训练后期尤其明显。随着训练的进行,网络获取到的信息越来越接近真实语义特性,那么此时的负样本更有可能是潜在的正样本(false negative),因此一个启示是可以随着迭代的次数增多而增大温度系数
A SURVEY ON CONTRASTIVE SELF-SUPERVISED LEARNING arXiv (Citations 31) ✅ 感觉偏重对CV领域进展的介绍,对NLP的介绍不足
图神经网络
- #TODO Graph Neural Networks for Natural Language Processing: A Survey arXiv
PyTorch
AllenNLP
Hugging Face Transformers
机器学习
优化算法
Adam那么棒,为什么还对SGD念念不忘 (1) —— 一个框架看懂优化算法 , 用一个框架总结了SGD -> SGDM -> NAG ->AdaGrad -> RMSProp -> Adam -> Nadam,下面公式中:theta为参数,g为梯度,m为一阶动量,V为二阶动量,alpha为学习率,beta_1为一阶动量系数,beta_2为二阶动量系数,下面的公式与作者原文略有出入 ✅
SGD with momentum,考虑了大约$1/(1-\beta_1)$个时刻的梯度的平均值:
SGD with Nesterov Acceleration,不直接计算当前位置的梯度方向,而是先计算按照累积动量走了一步那个时候的梯度方向,然后用这个点的梯度方向,与历史累积动量相结合做梯度下降。为什么要这么做呢?很明显在momentum里,我们知道当前参数一定要根据上一时刻的动量走一步,也就是 $ \beta_{1} \cdot m_{t} $ ,既然我都知道 $\theta$ 一定会走这步,为什么我不先走了之后再根据那的梯度再走呢?这主要是为了解决momentum梯度下降冲过头的情况,关于PyTorch实现Nesterov方式的讨论1:提出了nesterov的等价形式与讨论2:总结了一些issue与简单推导pdf,下面是详细推导,首先是Nesterov原公式
下面是其“等价”形式(至于为什么等价我还未完全明白),也是各大框架实现它的方式:首先令$\theta_{t}^{\prime}=\theta_{t}+\beta \cdot m_{t}$,则$m_{t+1}=\beta \cdot m_{t}-\alpha \nabla_{\theta_{t}} L\left(\theta_{t}^{\prime}\right)$,则:
最后再令$\theta_t=\theta^{\prime}_{t}$,就得到了$\theta_{t+1}=\theta_{t}+\beta^{2} \cdot m_{t}-(1+\beta) \cdot \alpha \nabla_{\theta_{t}} L\left(\theta_{t}\right)$,下面贴一张keras的实现代码
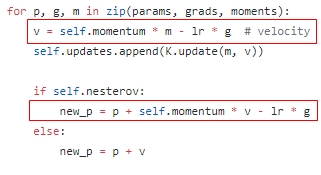
另一种视角,NAG本质上是多考虑了目标函数的二阶导信息:比Momentum更快:揭开Nesterov Accelerated Gradient的真面目 by 郑华滨 ✅
AdaGrad,学习率除以累积二阶动量,被更新越多的参数学习率越小,存在的问题是到最后二阶动量一直累积,导致学习率接近0,可能导致训练提前结束:
RMSProp,修正AdaGrad的问题,只考虑过去一段时间的二阶动量:
Adam,结合SGD的一阶动量与RMSProp的二阶动量更新公式,一般$\beta_1=0.9,\beta_2=0.999,m_0=0,V_0=0$,初期m和V都太接近0,因而使用下式进行误差修正:
NAdam,结合Adam与Nesterov Acceleration
Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略 ✅
- 稀疏数据优先考虑自适应学习率算法;使用自适应学习率算法一定要shuffle数据;可以先用小数据集实验;当验证集指标不变或下降时降低学习率
深度学习中优化方法——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam ,公式推导详尽,也给了示例代码和很多深度学习框架的源码,不错的一篇文章
An overview of gradient descent optimization algorithms by Sebastian Ruder
Fine tune trick
Discriminative fine-tuning
基本思想是针对不同的层在训练更新参数的时候,赋予不同的学习率。这里的出发点是,一般来说,对于NLP的深度学习模型来说,不同层的表征有不同的物理含义,比如浅层偏句法信息,高层偏语义信息,因此对于不同层的学习率不同,自然就是比较合理的了。先指定最后一层的学习率,然后根据下式得到前面层的学习率,基本思想是让浅层的学习率要更小一些。
Slanted triangular learning rates
- 类似于warm up,学习率先从0开始线性增加,然后线性减小,因此学习率画出图来是一个斜三角形
Gradual unfreezing
- 主要思想是把预训练的模型在新任务上finetune时,逐层解冻模型,也就是先finetune最后一层,然后再解冻倒数第二层,把倒数第二层和最后一层一起finetune,然后再解冻第三层,以此类推,逐层往浅层推进,最终finetune整个模型或者终止到某个中间层。这样做的目的也是为了finetune的过程能够更平稳。
杂项
他人撰写或收集的资料
- NLP-ability: 总结梳理自然语言处理工程师(NLP)需要积累的各方面知识,包括面试题,各种基础知识,工程能力等等,提升核心竞争力 by DASOU
- 李理的博客
- Resources to Help Global Equality for PhDs in NLP / AI
- 名校公开课程评价网, 项目github地址
- MIT 计算机教育中缺失的一课 中文版,英文原版,Video
- 最优化:建模、算法与理论
知乎专栏
- 醒醒啊,工头喊你搬砖了 by TheLongGoodbye,内容主要关于NLP,作者为哈工大博士
- 无痛的机器学习 by 冯超
PaperList
Github Repo
- 手写实现李航《统计学习方法》书中全部算法
- 2021年最新总结,阿里,腾讯,百度,美团,头条等技术面试题目,以及答案,专家出题人分析汇总
- 基于开源GPT2.0的初代创作型人工智能 | 可扩展、可进化
- 《机器学习实战》的python3源码
其他领域有趣的paper和工具
PaperRobot: Incremental Draft Generation of Scientific Ideas arXiv
苏剑林推荐论文
- Fast Model Editing at Scale
- Momentum Contrastive Autoencoder- Using Contrastive Learning for Latent Space Distribution Matching in WAE
- On some theoretical limitations of Generative Adversarial Networks
- SOFT- Softmax-free Transformer with Linear Complexit
- Conditional Poisson Stochastic Beam Search
- Sample Efficient Model Evaluation
- Scale Efficiently- Insights from Pre-training and Fine-tuning Transformers
- Controlled Text Generation as Continuous Optimization with Multiple Constraints
- Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization
- FMMformer- Efficient and Flexible Transformer via Decomposed Near-field and Far-field Attention
- The Separation Capacity of Random Neural Network
- Towards Zero-shot Language Modeling
- Noisy Channel Language Model Prompting for Few-Shot Text Classification
- Long-Short Transformer- Efficient Transformers for Language and Vision
- Rethinking positional encoding
- Simpler, Faster, Stronger- Breaking The log-K Curse On Contrastive Learners With FlatNCE
- Tight Mutual Information Estimation With Contrastive Fenchel-Legendre Optimization
- Variational Diffusion Models
- Alias-Free Generative Adversarial Networks
- Charformer- Fast Character Transformers via Gradient-based Subword Tokenization
- Conjugate Energy-Based Models
- Re-parameterizing VAEs for stability
- Stable, Fast and Accurate- Kernelized Attention with Relative Positional Encoding
工具
Vim
ycm
- brew进行upgrade或者安装包时有可能break ycm及对应的python包,解决方案:进入youcompleteme目录,用新的python install.py,注意不可用anaconda版python CSDN
- 更换g++或gcc版本时有可能break ycm的环境,需要重新指定CMAKE_C_COMPILER路径,也需要用python重装ycm
- https://github.com/Homebrew/brew/issues/2356
Unix实用命令
scp
- mac端使用rsync指定远程端口传输文件的命令为:rsync -e ‘ssh -p PORT’
ssh
- 端口转发,在远程服务器连接本机的梯子,本机的梯子代理端口为localhost:7890,则在本机连接远程服务器
ssh -R localhost:7890:localhost:7890 username@remote-server-ip,然后在远程服务器运行export https_proxy=http://127.0.0.1:7890 http_proxy=http://127.0.0.1:7890 all_proxy=socks5://127.0.0.1:7890,测试是否已经挂上本机的梯子wget www.google.com
paste
- 可以将文件所有行按分隔符合并成一行,或者按分隔符合并两个文件,例子:Merge two files side by side, each in its column, using the specified delimiter,
paste -d,基本用法见tldr
kill
- 根据进程名称关键词,批量打印所有要kill的进程,
ps -ef | grep | grep -v grep | awk '{print "kill -9 "$2}',批量kill这些进程ps -ef | grep | grep -v grep | awk '{print "kill -9 "$2}' | sh
科研技巧
三遍读论文(by 李沐)
- 第一遍读title,abstract和conclusion,看看是否是自己感兴趣的以及效果怎么样,可以再看一看method和experiment里的图表
- 确定是自己感兴趣的之后,第二遍从头开始读,不要太注意细节比如公式和证明,但要完全理解重要的图和表都在干什么,作者是如何与别人对比的,差距有多大,可以把作者提到的重要相关文献圈出来,比如作者做的问题就是这些文献里提出来的,或者作者是根据这些文献进行的改进
- 第三遍,这篇文章值得完全搞懂,要明白文章的每一句话,并且想象自己在实现这篇文章,作者根据xx问题提出的xx方法,如果换我来解决这个问题我怎么做,作者说留着future做的工作,如果我来做怎么做